前言
最近在关注LLM Security,发现网上文章偏理论, 缺乏漏洞落地和利用,以及对应的防御方案,让我甚是苦恼。
所幸,最终发现了360研究院发布的《大模型安全漏洞报告》,其中关键点是对大模型自身的安全立了框架,将其分为模型层、框架层和应用层,笔者以一个初学者的角度,根据这个框架,辅以一些实际的漏洞demo进行学习和理解。
模型层
模型层安全问题
- 数据投毒 :例如在开源平台发布携带虚假标签数据的训练集,从而影响模型的判断。
- 数据泄露:常见的 prompts 注入,泄露系统提示词以及其他信息
- 模型后门:将后门模型发布在hugging-face上,通过特定提示词可以触发攻击者预设的结果。
- 对抗攻击:小幅修改输入数据,使得模型产生错误预测。
这一部分没办法实践,缺乏实际的模型训练经验。
框架层
框架层安全问题:
- 处理不可信数据:例如 transforms 不止一次爆出了反序列化漏洞,本质是加载不可信数据导致的 pickle 反序列化。
- 分布式场景下的安全问题:llamma.cpp、Horovod、Ray,这个我没看。
transformer 反序列化 RCE
transformer <= 4.38.0( CVE-2024-3568 )存在 checkpoints 反序列化漏洞,本质是 pickle 反序列化。
1 | git clone git@github.com:llm-sec/huggingface-hacker.git |
vul.py 漏洞环境代码
1 | from tensorflow.keras.optimizers import Adam |
成功弹出计算器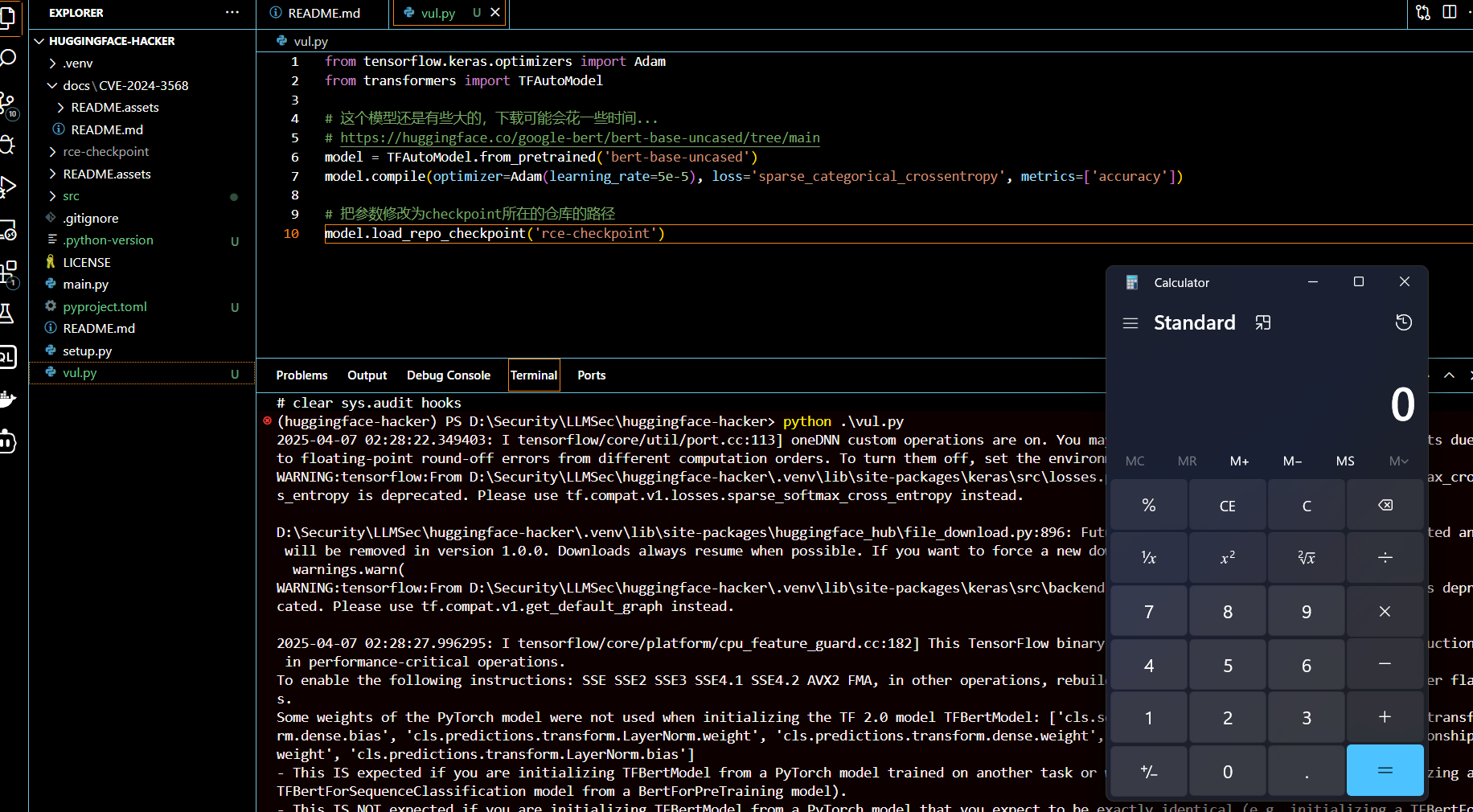
防御措施:对于pickle反序列化漏洞,一是不要反序列化不可信的第三方数据,二是就是通过重写Unpickler.find_class()来限制全局变量,达到 hook 的效果。
1 | import builtins |
应用层
应用层安全问题:
- 本质上和传统的Web安全没什么区别,照样是SQL注入、RCE、API泄露等。
- MCP Server:可能存在接口未授权,example 样例是有这个问题的,具体得看 MCP Server 的实现。
- ollama:api未授权导致公网模型可以被薅羊毛,直接用 chatboxai 即可链接使用。
MCP Server 接口未授权
MCP 即 Model Context Protocol 模型上下文协议,简单理解就是在 LLM 和 数据源之间加了一个标准化的中间层,也就是我们的 MCP Server。
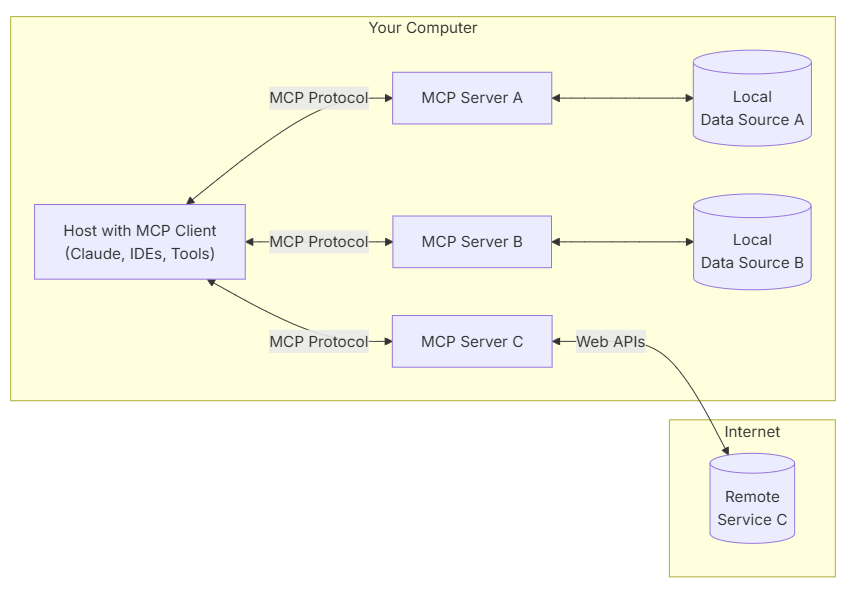
Why MCP?这里通常和 Function Call 做比较,其实他们在功能点上并无太大差异,主要是 MCP 实现了标准化,每个数据源提供各自的统一接口(MCP Server),LLM只需要实现一个接口(MCP Client)即可和任意的数据源做交互,简化了交互的复杂程度。一图胜千言: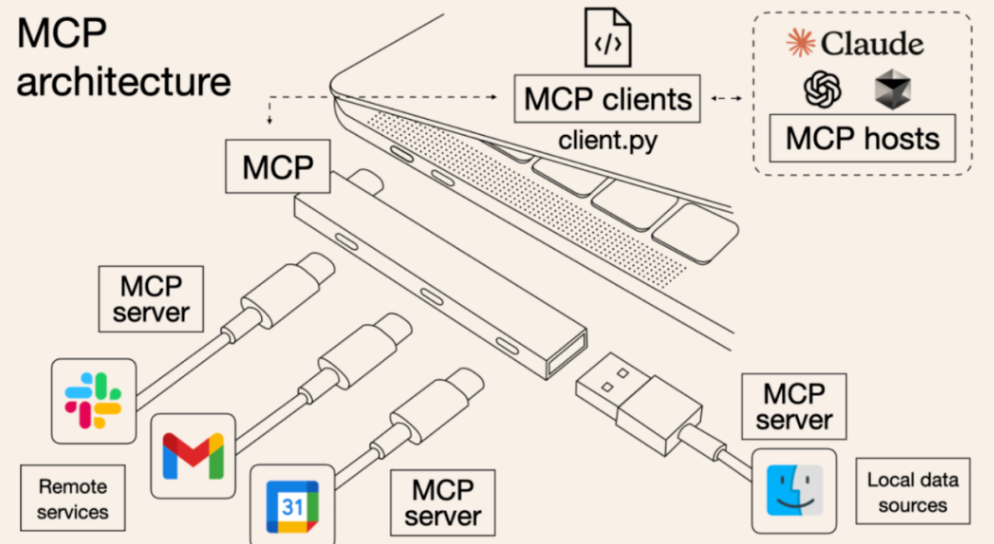
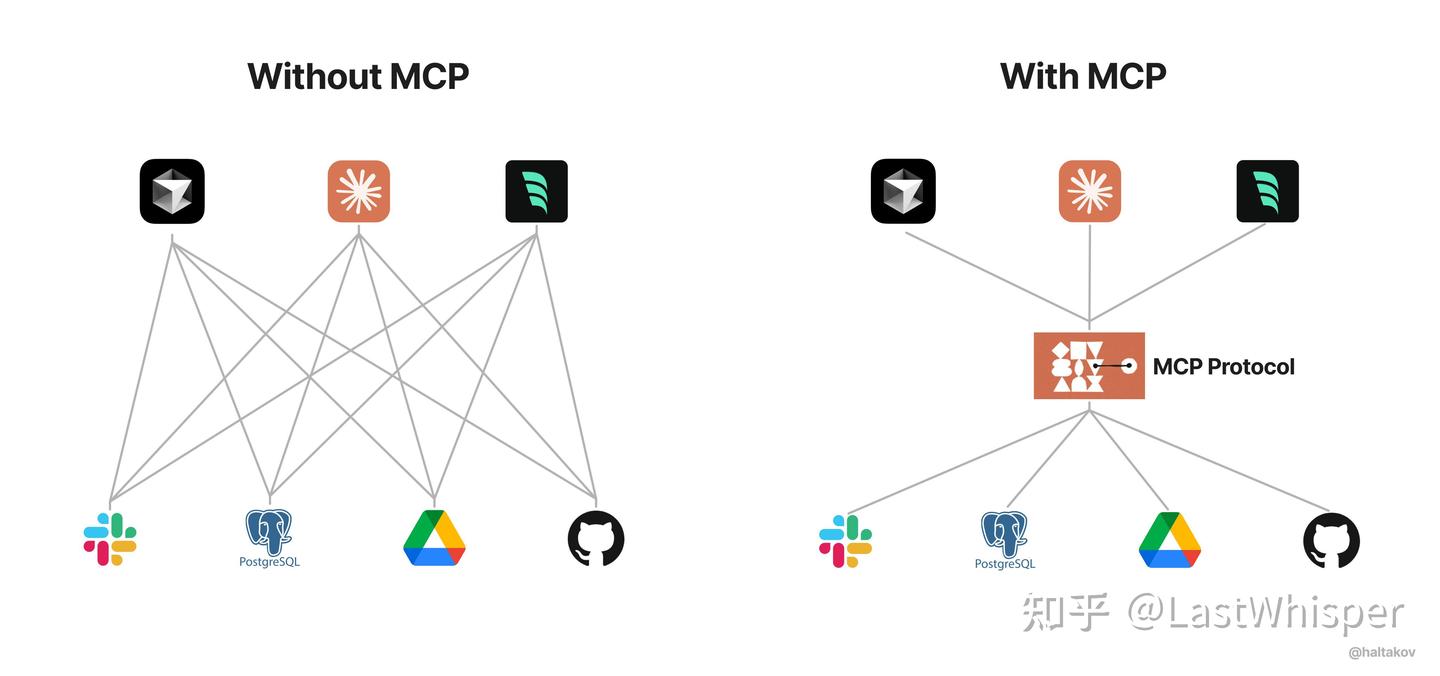
MCP Server 本质上就是一个 TypeScript / Python /Java 编写的一个 Web 服务,所以也会存在对应的Web安全问题。MCP Server 目前存在两种 transport: stdio 和 sse,简单理解就是一个本地子进程调用,一个远程调用。
[Firebasky](Firebasky (Firebasky)) 师傅在星球提到 Python MCP Server 在 transport = sse 的时候,会统一暴露 8000 端口,并且 api 接口没有做鉴权或其他防护,这就意味着如果公网存在类似的 MCP Server,则可构造 API 调用 MCP Server 的功能,由于MCP Server 的代码是开源的,根据 Server 源码构造 Payload 显然并非难事。
这里以 python-sdk 里的 demo 为例,server.py 里存在访问网站的功能,自行构造 clinet.py ,可以实现 SSRF。
可以看到,SSE的模式下,不需要任何鉴权即可调用 Server API,这个服务器肯定要加鉴权的。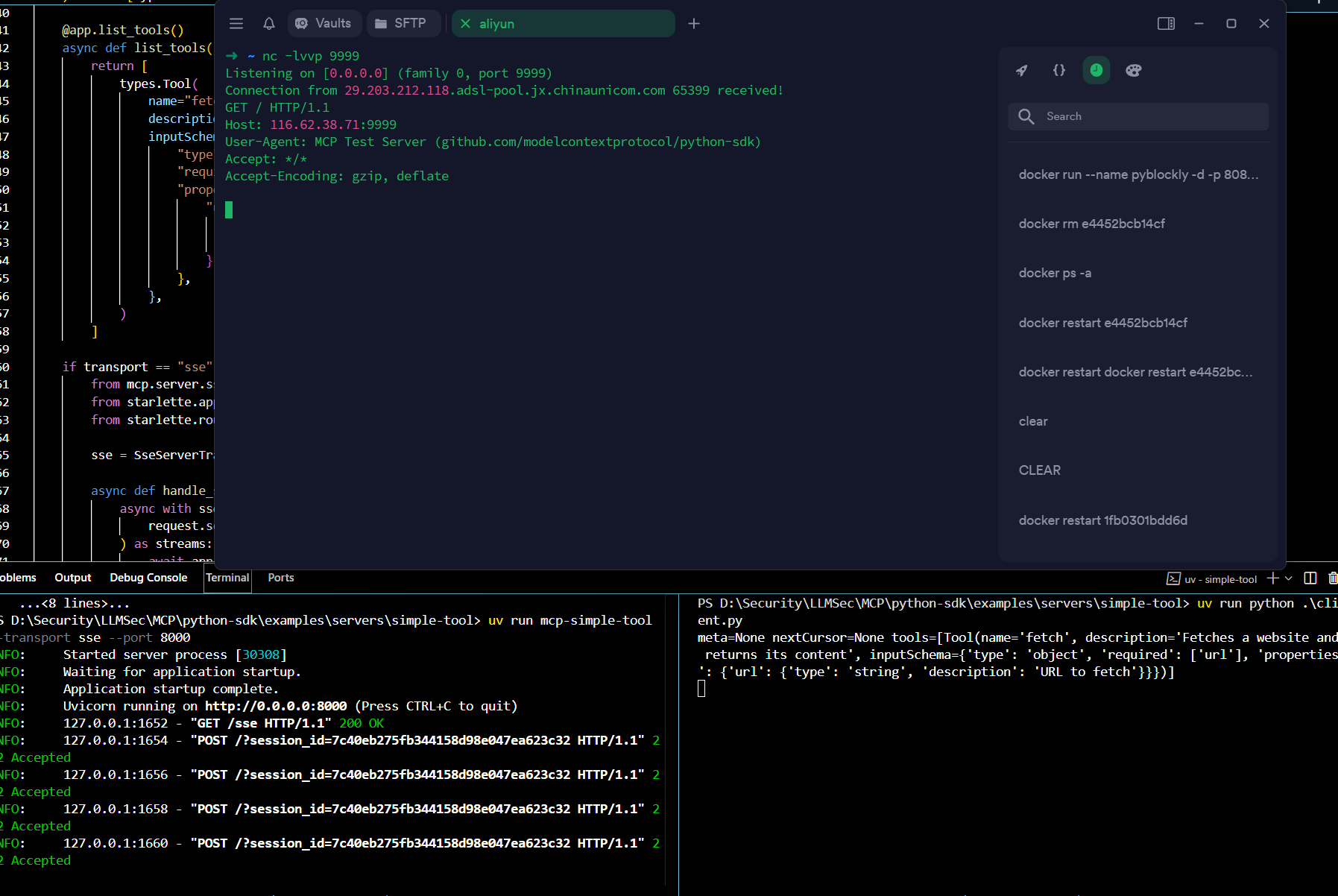
java SDK 在样例中给出如何在 SSE 模式下给 api 添加权限的校验,使用的是 OAuth2,需要考虑一下每次调用工具都要验证,这个开销问题如何解决。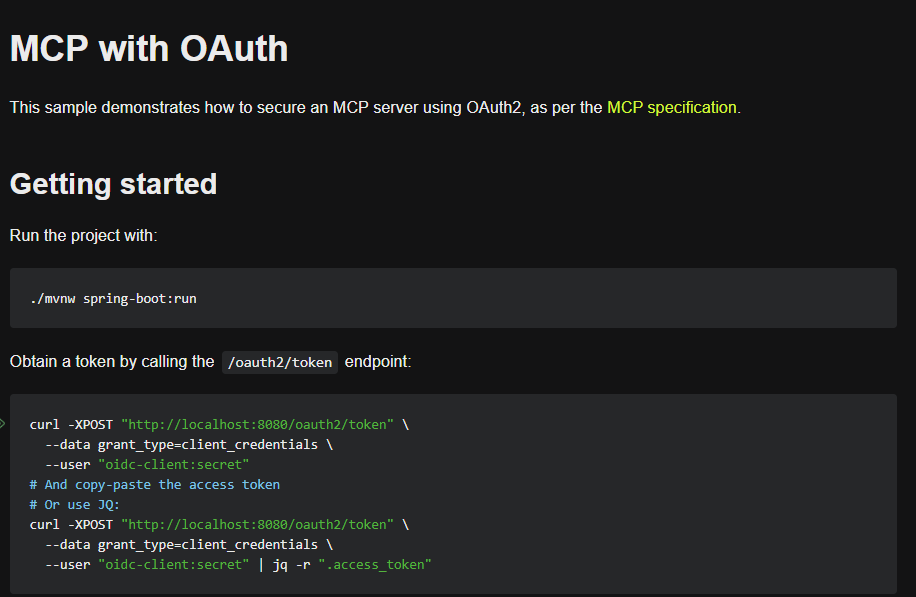
至于 TS 的 Server,目前还搞不明白,环境没搭好,这个得看一下 typescript 的项目搭建。
防御措施:对于必须远程部署的server,可以尝试白名单ip访问,同时添加权限校验。
ollama 接口未授权
这个直接 fofa 远程搜索进行复现:app="Ollama", 先 /api/tags 查找模型,然后尝试查询:
1 | POST /api/chat |
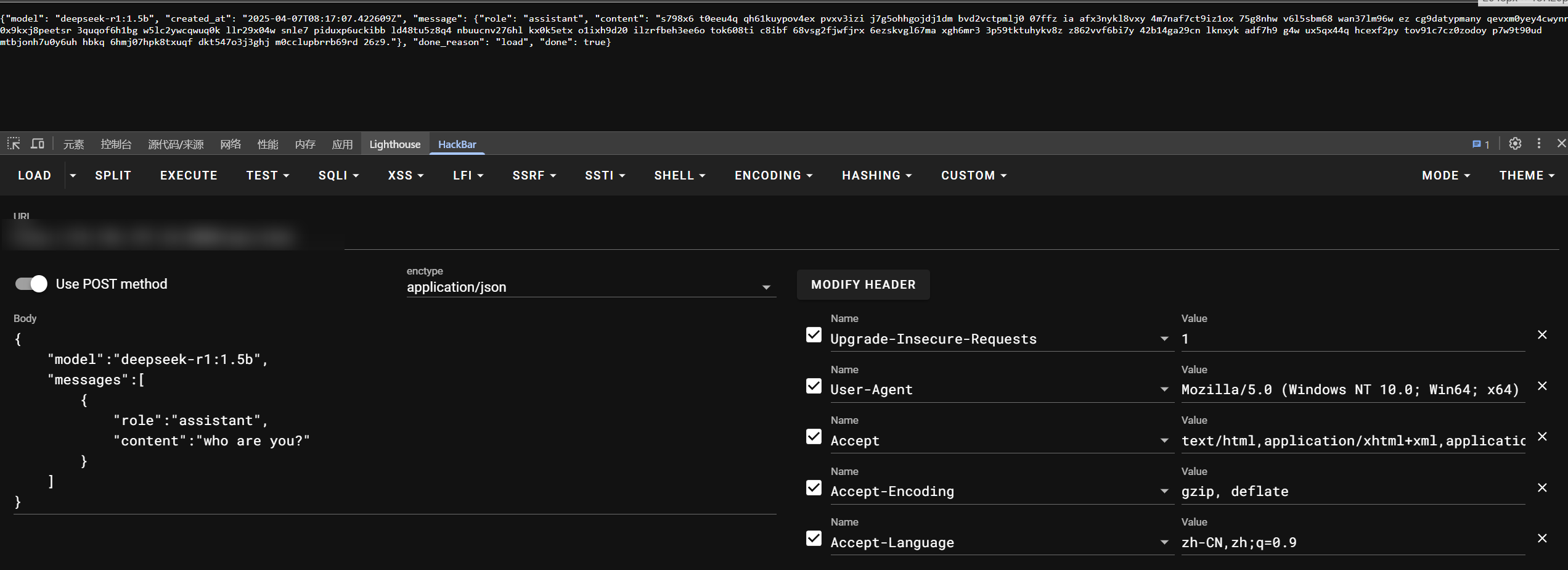
防御措施:禁止任意公网IP访问、采用 IP 白名单、添加 OAuth2等